2024. 10. 5. 20:25ㆍAI/LLM
학기에 두 번 있는 paper 발표.
나는 주제로는 Instruction finetuning, 논문은 SELF-INSTRUCT: Aligning Language Models with Self-Generated Instructions(ACL 2023)을 주제로 발표했다.
Instruction finetuning은 기존의 random format의 natural language text dataset을 이용한 finetuning이 아닌 Input-Insturction-Output으로 구성된 하나의 instruction set을 이용한 finetuning을 말한다.
Instruction finetuning에 대한 내용 설명은 앞 조원분이 발표해주시고, 나는 Language model이 스스로 instruction set을 생성하는 논문을 발표했다.
요약
- Instruction set을 이용한 pretraining은 좋은 성능을 보여왔지만, 비싸다.
- Language model이 instruction set을 스스로 만들어 보게 하고, 만든 set으로 스스로 학습하게 했더니 결과가 좋았다.(NLP task 성능 향상, 만들어진 instruction set의 다양성, robustness 충족)
해당 논문에서는 LM generated instruction set을 여러개의 heuristic을 써서 filtering하는데, 다른 LM에게 만들어진 instruction set에 대한 채점을 맡기는 새로운 논문들이 나왔다. 이는 다음 포스트(해당 주 RQ)에 서술할 예정.
Q&A
발표가 끝나고 학생들과 교수님들과의 Discussion 시간이 있었는데, 기억나는 것만 적어본다.
Q: Machine generated instruction set을 이용한 train의 단점?
A: 논문에도 나오듯 Language model이 가지고 있는 bias/weakness들이 더욱 증폭될 수 있다.
Q(교수님): 모든 Training data set이 instruction set 형식이면, instruction finetuning이 필요할까?
다른 조원 분이 답변을 하셔서 말씀은 못드렸지만, 필요없을 것 같다는 생각을 하고 있었는데 교수님도 필요없다고 생각한다고 하셨다. 현재는 뒤죽박죽 되어있는 모든 natural language를 가지고 pretraining을 하고 everyday NLP task에 적합한 대답을 내놓도록 LM을 학습시키기 위해 Instruction finetuning을 하는거라, 굳이 필요 없을 것 같다는 생각이 들었다.

I’ll introduce a paper that automates this instruction finetuning process.
Self-instruct: aligning language models with self-generated instructions was published to ACL in 2023.

Instruction based finetuning shows nice performance in various NLP tasks.
However, obtaining instruction data of good quality and quantity is often expensive and hard to earn. Human annotators are needed to generate instructions and Many of instruction dataset made for academic purpose are focusing in only some of NLP tasks like classification and summarization
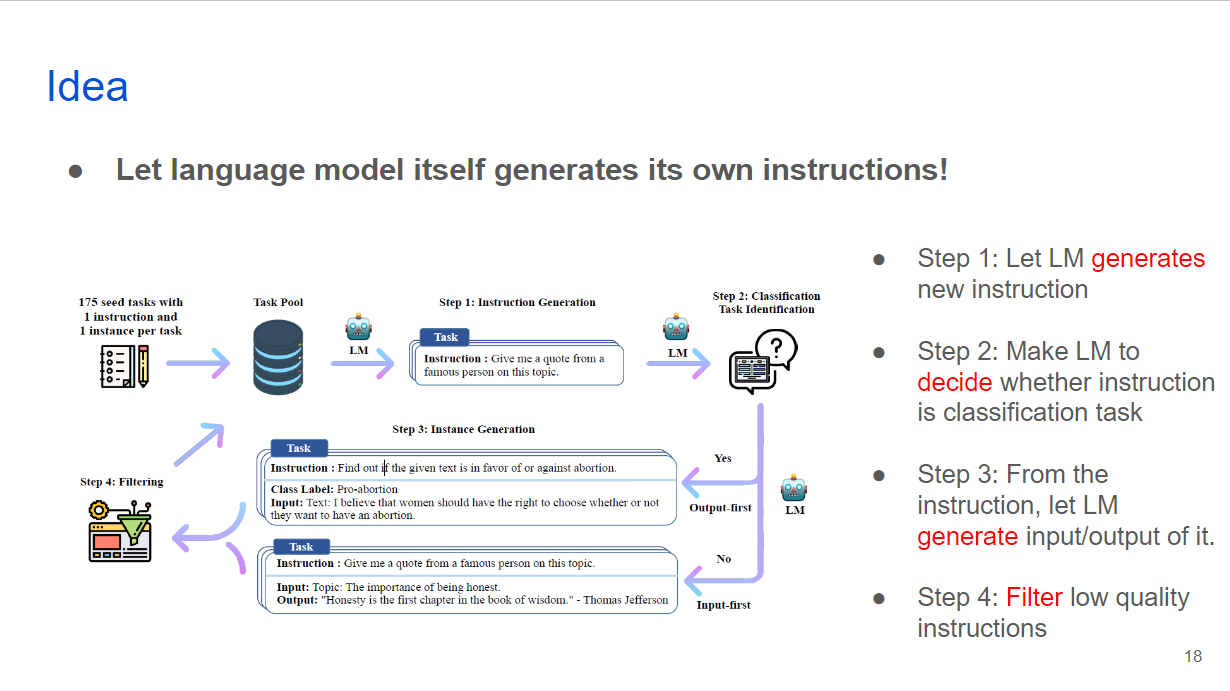
So, idea of the paper is simple. Let the language model itself generates its own instructions.
Left side figure shows an automatic process of generating instructions.
Step 1 is let language model generates new instruction. In this example, its ‘Give me a quote from a famous person on this topic’.
Step 2 is Making language model to decide whether instruction is classification task. I’ll explain later why this step is needed.
Step 3, From the instruction, let language model generate input and output from it.
Step 4, Filter low quality instructions.

Baseline language model is vanilla GPT3 with 175 billion parameters.
In the first, there should be small set of human written instructions as a seed set.
Left side is a sample prompt of step 1. To improve stability and quality of instructions, human written instructions are prompted with language model generated instructions. From task 1 to 6, they are randomly selected from seed set of human written instructions. From other two tasks are from language model generated task set. And ask language model make task 9.

With the generated instruction by previous step, researchers made Language model to generate following input and output. However, a number of instructions specifically in classification task, generates biased output, which means language model only generates one class of output.
Therefore, for the other tasks, researchers made language model to generate this order. Instruction, input, output. For the classification tasks, they made language model to generate outputs first.

After decision of whether instruction is classification tasks or not, now language model generates following input and output. Instruction in first picture is to suggest a better and more professional rephrasing of the following sentence. Then language model generates input sentence: “This house is surprisingly not constructed very well, bla bla”. After that, it generates output by instruction and suggested input. Which is “This house does not seem to be constructed well, etc”.
Second picture is about classification task. Instruction wants to classify the sentiment of the sentence. In this task, as mentioned in previous step, language model generates output first, which is ‘class label’ in this example. And then, the input comes out. In this case: Sentence: I enjoy the flavor of the restaurant but their service is too slow.

After language model generates this instruction set which is composed of instruction, input, output, it has to be filtered. Authors used some heuristics for this like filtering too short or too long, same input in but different output out, too similar to existing instruction set, or instructions that contains word like images, videos, graphs or any kind of data source that language model cannot use.
If this newly generated instruction set passes filtering, it is added to existing instruction set and used for generating new instruction in future.

Left is top 20 common verbs of generated instruction. You can see the examples like write a function, give an example, find word. By the way, there are a lot of verbs and nouns about programming. Write a function, create program/algorithm/function, design an algorithm. It seems there were quite a number of codes when training language models. Anyway, back to the topic. Upper right is the distribution of similarity between language model generated instruction and its most similar human written seed instruction, which is quite low.
Lower right is lengths of instruction, input, and output.
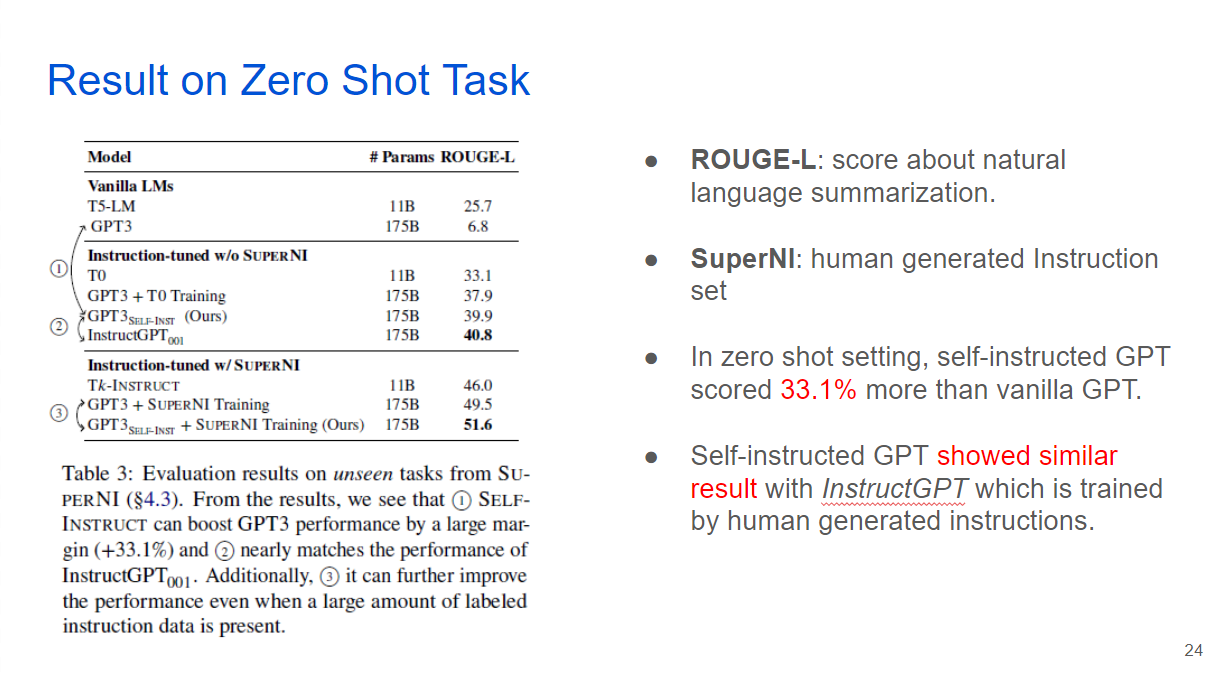
This is result comparison of vanilla GPT3 and self-instructed GPT and human-instructed instructGPT on SuperNI dataset. For the vanilla GPT3, ROUGE-L score, which is about language summarization is 6.8, but self-instructed GPT3 had 39.9. which is similar to InstructGPT which is 40.8.

Researchers conducted experiment on more general tasks like writing emails, social media posting, programming for evaluation, because Super NI, previous slide’s evaluation dataset is mainly composed of academic topic and focuses on specific tasks like classification.
Left paragraph shows self-instructed GPT3’s performance is good enough. The green is A which is correct and satisfying response, blue is B which is acceptable response with minor imperfections. However, this A,B,C,D evaluation was conducted by authors themselves, so its result should be interpreted with caution.
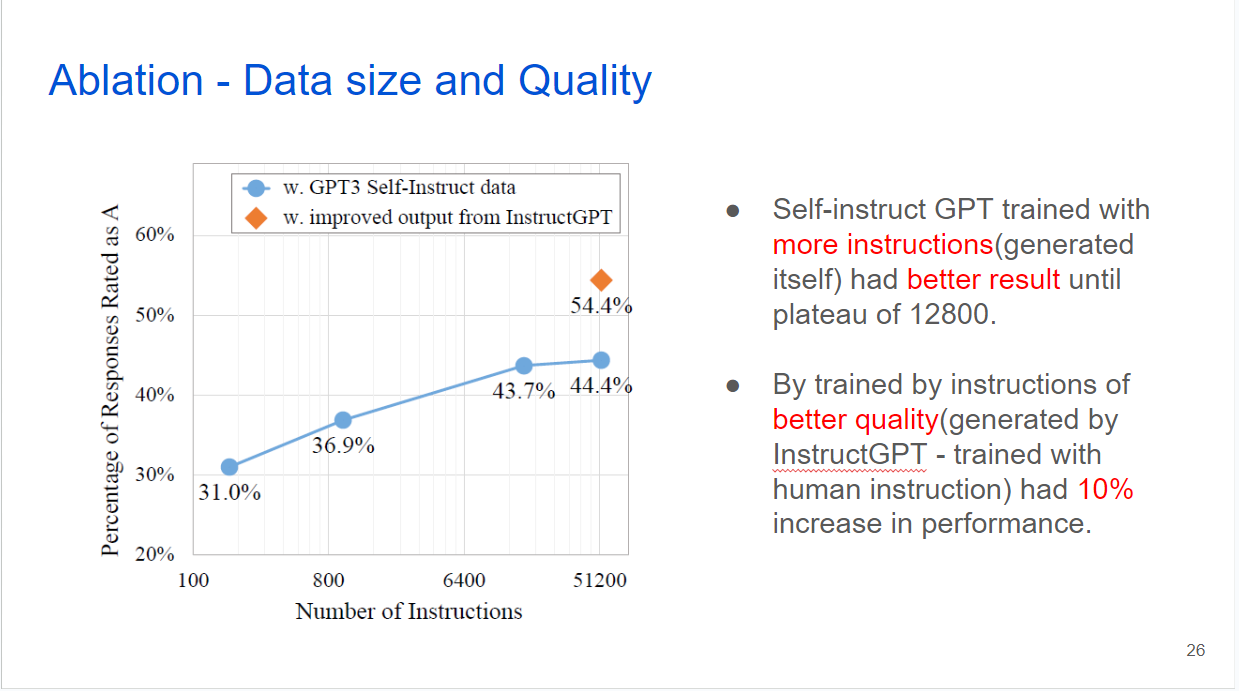
They did ablation study about data size and quality. Graph’s x axis is log number of instructions and y axis is percentage of rated as A. As you can see, percentage of A increases along with thenumber of instructions. For the quality aspect, GPT3 model trained with instructions generated from InstructGPT has better performace. InstructGPT is the model trained with human instructions and showed better performance in zero shot task and general tasks before.

Language model trained with instruction made by itself has significantly better result than its vanilla model, and similar result with human generated instructions.
This shows that there is a possibility to train language model with much less human annotated instructions which can dramatically reduce the costs of training.
'AI > LLM' 카테고리의 다른 글
| Reasoning and Planning - Paper 발표(Let’s Verify Step by Step) (0) | 2024.10.05 |
|---|---|
| Instruction finetuning - RQ (1) | 2024.10.05 |
| Decoder model vs Encoder-Decoder model RQ 발표 (0) | 2024.10.05 |
| Relative Positional encoding RQ 발표 (0) | 2024.10.05 |